dbt is a command-line tool. Yet many teams end up paying “platform tax” to run it: per-seat, per-run, per-environment fees, plus separate costs for scheduling and triggers. If your goal is simply reliable dbt pipelines—scheduled or triggered by an API—you can build a lean runner with AWS primitives and Kubernetes Jobs on EKS Fargate.
What we're building?
A small "dbt runner" system
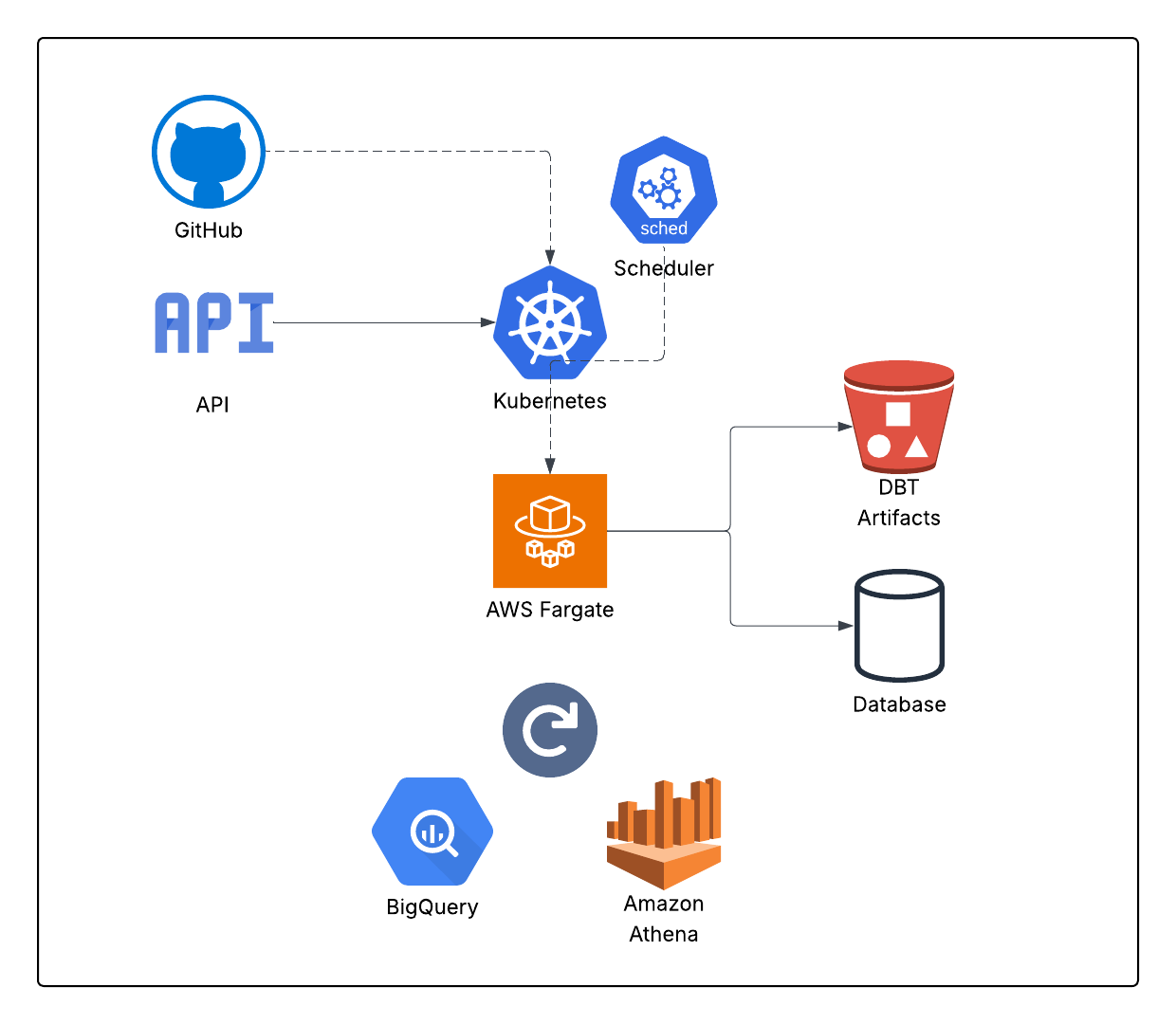
API Trigger → Kubernetes Job (Fargate) → dbt → artifacts to S3 → run metadata
Two ways to start runs:
- API-triggered (webhook, backfill, manual, CI/CD)
- Scheduled (cron-like runs using Kubernetes CronJobs)
Each run is a short-lived Kubernetes Job. Nothing stays up when no one is running dbt.
Why EKS Fargate for dbt
Fargate is a great fit for dbt because dbt workloads are:
- bursty (runs happen on schedules, not continuously)
- container-friendly
- easy to parallelize by environment/model selection
- mostly CPU/memory bound (especially for compilation + adapters)
With Fargate you pay for requested CPU/memory while the pod is running, not for idle nodes. That's the core cost win.
Core architecture
1) "Runner" container
- dbt + your adapter (e.g., postgres, bigquery, snowflake)
- your dbt project code (baked in or pulled at runtime)
- a small entrypoint script to:
- run dbt deps
- run dbt run / dbt build / dbt test
- upload target/ artifacts to S3
- emit run metadata (status, start/end, invocation id)
2) Trigger layer
- a tiny API service (FastAPI / Lambda / API Gateway) that calls Kubernetes API
- or kubectl from CI/CD (GitHub Actions) if you want even simpler
3) Scheduling
Use Kubernetes CronJob for schedules. It's native and cheap.
4) Observability + artifacts
- logs: CloudWatch (via Fluent Bit / Container Insights) or your existing log stack
- artifacts: S3 (manifest.json, run_results.json, catalog.json)
- optional: a small table for run history (Postgres/DynamoDB)
Minimal Kubernetes Job spec (pattern)
A dbt run is just a Job with environment variables and secrets mounted (warehouse creds, git token, etc.):
- DBT_COMMAND=build
- DBT_TARGET=prod
- DBT_SELECT=tag:daily
- EXTERNAL_RUN_ID=<idempotency key>
- mount secrets (warehouse creds)
- mount a service account (IRSA) for S3 writes
Key idea: every run is immutable and short-lived.
API-triggered runs
An API-trigger is simply: "create a Kubernetes Job".
You don't need a heavy orchestrator UI to do this. A tiny service can expose:
- POST /runs → creates a Job
- GET /runs/:id → returns status (read Job + logs link)
- POST /runs/:id/cancel → deletes Job
Nice-to-have behaviors
- Idempotency key: if external_run_id already exists, don't start a duplicate run
- Concurrency controls: cap runs per env (e.g., only 1 "prod" run at a time)
- Run parameters: allow select/exclude/state-based runs
Scheduled runs with CronJobs
CronJobs give you:
- retry policy
- concurrency policy (Forbid/Replace)
- history limits
- schedule in one YAML file
That's often "good enough" for daily/hourly dbt builds without Airflow/Dagster/etc.
Cost optimization tactics that matter
This is where you really win compared to paying an external platform:
1) Right-size requests
dbt pods should request what they use. Start with:
- 1–2 vCPU
- 2–4 GB RAM
then tune based on actual run time and memory.
2) Control concurrency
Unbounded concurrency is the fastest way to create surprise costs.
- per-env limit (prod = 1, staging = 2–3)
- per-team or per-tenant caps if multi-tenant
3) Avoid always-on nodes
Fargate means no idle node costs. If you do use EC2 nodes for some workloads, keep dbt on Fargate anyway.
4) Artifact retention
Don't keep artifacts forever in expensive storage classes.
- keep 7–30 days "hot"
- archive or expire older runs
The "don't overpay" argument (how to frame it)
A lot of platforms bundle:
- triggering
- scheduling
- logs
- artifacts
- run history
…but all of those are already available in AWS + Kubernetes with very little code.
What you should pay for is the hard stuff:
- warehouse costs
- good modeling
- testing and data quality
- observability that your team actually uses
Not "a button that runs dbt".